
何永忠, 李响, 陈美玲, 王伟. 基于云流量混淆的Tor匿名通信识别方法
4 实验评估4.1 实验环境
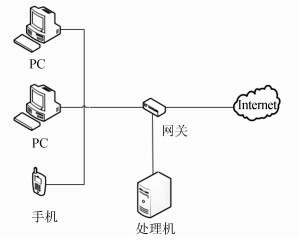
内网通过网关连接至Internet,流量采集程序部署在网关上,这样做可以采集到该局域网内所有的网络流量。对于网关所捕获的网络流量,由一台处理机对其进行识别和分类处理。系统网络拓扑如图3所示。
4.2 流量识别的评价标准
本文将使用召回率 (recall) 和准确率 (accuracy) 两项指标来评价识别结果。计算方法如下:
其中,TP为被分类器正确地划分为正例的实例数,TN为被分类器正确地划分为负例的实例数,FP为被分类器错误地划分为正例的实例数,FN为被分类器错误地划分为负例的实例数。
4.3 基于特征匹配识别的实验评估基于特征匹配的Tor匿名通信识别方法分为:基于Meek TLS静态特征的流量过滤和基于Meek流动态特征的流量识别两个步骤。
算法首先通过基于Meek静态特征的流量过滤后,目的是排除非Meek流的干扰,这样就只需对少数剩下的流量再做进一步的识别判断。因为该过滤方法无法对使用相应版本的Firefox浏览器访问Amazon等云服务时所产生的TLS流和Tor-Meek流进行有效区分,因此需要进一步采用基于Meek流动态特征的流量识别步骤。该步骤的核心是检测一条待识别流中是否含有Meek的轮询请求机制特征。为了验证流动态特征的特异性,本文对捕获的所有TLS流都进行了测试,包括通过Meek TLS静态特征过滤的TLS流和未能通过过滤的TLS流。实验发现,除Meek流之外,任何其他的TLS流都未能满足轮询请求机制的识别条件。
4.3.1 不同长度流的识别准确率本组实验的目的是考察不同长度的Meek流的识别效果。分别将Meek流按长度分为小于40个包、40~99个包、100~199个包、200~299个包、300~399个包和大于400个包的Meek流。本组实验样本中一共包含522条IPv4的Meek流和5 217条IPv6的Meek流。
分别计算以Meek流发起第1到第11次轮询请求机制作为识别准则的准确率。例如,以发起第3次轮询请求机制作为判断标准,那么,如果一条待识别的Meek流发起轮询请求机制并增长到第3次,则认定该条流为Meek流。计算结果如图4和5所示。
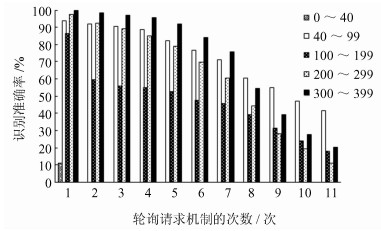
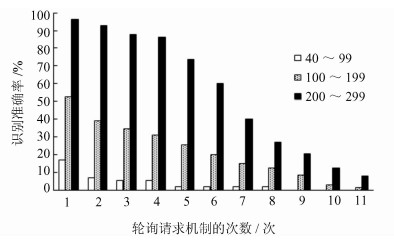
当判定准则设定的轮询次数越多时,就会有更多的Meek流被漏报,因此准确率就越低。对于相同的轮询次数,对于长度小于40个包的Meek流,产生的轮询请求机制次数很少,其中,IPv4环境下为0;。对于长度大于200的Meek流,有90%以上都发起了第2次轮询请求机制。而且长度越长的Meek流,所发起轮询请求机制的次数越多,识别的准确率越高。
4.3.2 不同Tor Browser版本的识别准确率本组实验的目的是考察不同Tor Browser版本以及不同Meek网桥的Meek流的识别效果。实验数据包含Tor Browser 4.2 Meek-Amazon、Tor Browser 4.2 Meek-Azure、Tor Browser 5.2 Meek-Azure、Tor Browser 5.5 Meek-Azure、Tor Browser 6.0 Meek-Azure的Meek流,共5 739条。计算方式与4.3.1节相同,计算结果见如图6。
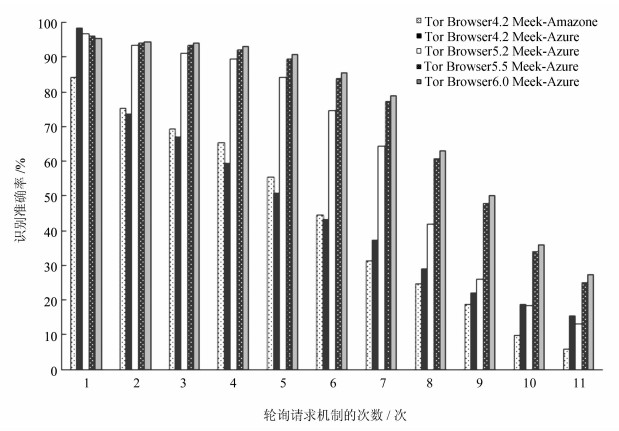
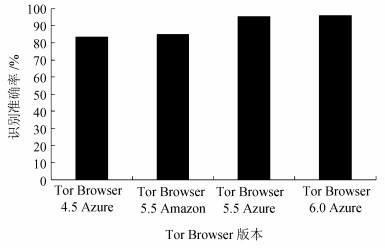
通过实验结果可以发现:对于Tor Browser 5.X和6.X版本的Meek流,有90%以上都发起了第2次轮询请求机制。对于Tor Browser 4.X版本的Meek流相对较低,有70%以上发起了第2次轮询请求机制,分析其原因,主要是在实验时Tor Browser 4.X版本过相对较旧,因而连接状态不稳定,产生了大量的重传包对识别效果造成了影响。
4.3.3 基于特征匹配的识别准确率通过以上2组实验的结果可知:对于长度较短 (小于40个包) 的Meek流,一般检测不到Meek的轮询请求机制;对于长度大于200个包的Meek流,有95%以上可以检测到第2次Meek的轮询请求机制。结合Meek的连接特性来看,可以认为对于长度过短的Meek流是无效的Meek流,因为即便该TLS流是Meek流,但它不可能通过40个以内的数据包完成Tor连接的建立过程,更不能进行后续访问Tor的操作,所以对长度过短的TLS可以直接排除。在排除长度小于40个包的流之后,对不同的Tor Browser版本识别的准确率如图7所示。
4.3.4 实时性分析
基于流特征的识别的计算主要集中在对轮询请求机制的判断上。为评价该方法的识别时间性能,本文对平均长度为314个包的SSL流执行1×105次轮询请求机制判断,在除去IO操作的耗时后,共耗时706 ms。基于流特征的识别方法具有较好的实时性。
4.4 基于SVM识别的实验评估基于特征匹配的识别算法容易受到版本变化与更新的影响,本文第3节提出基于统计特征的分类算法可以有效解决该问题。基于SVM的Tor匿名通信识别的关键部分是SVM分类器的构造和特征值的选取。对于SVM分类器,使用LibSVM工具包,选择C-SVC,线性核函数。之后对于惩罚系数c的选择,使用不同的值进行多次训练和检测,根据检测结果选取最优解,c按2的指数次幂进行取值,变化范围从20到210。
4.4.1 分片大小对识别准确率的影响
在基于Meek流分片的模型中,分片的大小将对识别的结果将产生直接的影响,分片过大或者过小,都会使识别的准确率下降。为了选择最佳的分片大小,需要对不同的分片大小分别进行了测试。本次实验使用1 000条Meek流和200条非Meek流作为训练样本,分片大小分别取20、30、40和50个数据包,之后对不同的分片大小和惩罚系数c的组合分别进行多次训练和检测。检测结果见表2。
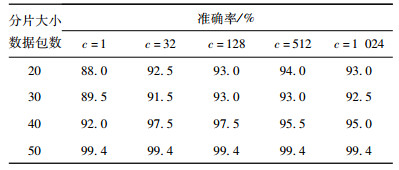
由检测结果可以看出,识别的准确率随着分片大小从20增加到50是依次递增的,当分片大小为40时,识别的准确率可以达到97.5%(c=32或128时),当分片大小为50时,识别的准确率可以达到99.4%。因此,基于Meek流分片模型的识别方法,对于Meek流的识别有较高的准确率。
发表评论